Utiliser les logiciels
Utiliser R
R est installé avec le compilateur INTEL. Pour charger R vous devez utiliser la commande : module load intel/2021.1 r/4.0
Pour pouvoir installer vos paquets R localement sur votre home :
Créez un dossier sur votre compte :
mkdir ~/MyLibsRCréez le fichier ~/.Rprofile contenant la ligne suivante : .libPaths(« ~/MyLibsR »)
Une fois R lancé, utiliser la commande :
install.packages(<pkg>,dependencies = TRUE,clean=TRUE,repos =<adresse du site>)
Par exemple install.packages("accuracy",dependencies = TRUE,clean=TRUE,repos = "http://mirror.ibcp.fr/pub/CRAN/)
L’installation se fera dans le dossier ~/MylibsR
Utiliser Python
Python est installé avec la distribution Miniforge. Pour charger python vous devez utiliser la commande module load miniforge/24.11
Miniforge
Vous pouvez utiliser une version installée en standard sur le cluster ou installer votre propre version sur votre compte.
Installez votre version de Miniforge
Vous pouvez télécharger ici l’installeur de Miniforge et suivre la procédure d’installation indiquée. La suite des explications de ce document est donnée en partant du principe que vous utilisez la distribution disponible sous forme de module. A vous d’adapter les explications si vous utilisez votre version de Miniforge.
Utilisez la version de Miniforge installée en standard sur le cluster
Une version a été installée pour vous. Pour l’utiliser : module load miniforge/24.11
Environnements préexistants
Des environnements virtuels conda ont été créés. Pour avoir la liste des environnements virtuels
existants : conda env list
Vous trouverez notamment 2 environnements virtuels disponibles pour les nœuds gpu-intel et gpu-amd pour les applications tensorflow (tensorflow-gpu-env) et py-torch (pytorch-env)
Note
ces environnements seront peut-être incomplets pour vos usages (packages supplémentaires nécessaires). Dans ce cas il vous faudra créez vos environnements virtuels sur votre compte
Configurez votre espace de travail pour faire des environnements dans votre compte
Pour pouvoir installer vos packages python localement sur votre compte :
Créez un dossier sur votre compte :
mkdir -p ~/conda_env/.condaFaire un lien symbolique vers .conda :
ln -s ~/conda_env/.conda ~/.condaAvertissement
Il peut être utile de supprimer le .conda existant ou d’en copier le contenu dans ~/conda_env/.conda
Créez une variable d’environnement :
export CONDA_ENVS_PATH=$HOME/conda_env/(Vous pouvez ajouter cette variable dans votre ~/.bashrc pour ne pas avoir à la saisir à chaque fois)Chargez le module :
module load miniforge/24.11Créez votre environnement virtuel en spécifiant le chemin :
conda create --prefix=${CONDA_ENVS_PATH}/test-3.6 python=3.6Pour charger cet environnement :
conda activate ${CONDA_ENVS_PATH}/test-3.6Pour quitter cet environnement :
conda deactivate
Notebook
Préparez vos environnements virtuels afin qu’ils soient utilisables dans les notebooks
Si vous voulez utiliser vos environnements virtuels dans un notebook vous devez :
Chargez votre environnement virtuel (nommé nom_env):
conda activate ${CONDA_ENVS_PATH}/nom_envInstallez ipykernel dans cet environnement virtuel:
conda install ipykernelLiez votre environnement virtuel à jupyter :
python -m ipykernel install --user --name=nom_env(L’environnement virtuel doit être actif)Installez le module notebook :
conda install -c conda-forge notebook
Lancez un serveur jupyter sur des ressources dédiées
Créez un script de soumission SLURM (my_notebook.job) pour votre jupyter notebook en décrivant les ressources dont vous avez besoin
#!/bin/bash ## nombre de noeuds #SBATCH --nodes 1 ## AJOUTER LA RESSOURCE GPU (#SBATCH -p gpu-intel --gres=gpu:1 ou #SBATCH -p gpu-amd --gres=gpu:1) ## ##nombre de coeurs #SBATCH --cpus-per-task 2 #durée de votre notebook #SBATCH --time 02:00:00 #nomde votre notebook #SBATCH --job-name my_jupyter_notebook # on charge le module Miniforge module load miniforge/24.11 #on lance le serveur jupyter (sans le navigateur) sur le port 8080 #on pouvait utiliser un autre port, de préférence supérieur à 8080 jupyter notebook --no-browser --port=8080 --ip=$(hostname -s)
Soumettre votre job
sbatch my_notebook.job: cette commande vous attribue un jobid et génère un fichier slurm-jobid.out où sont redirigées les sorties de votre job.Deux informations sont à récupérer dans le fichier : le nœud sur lequel s’exécute votre job (nodexx ou gpu0x) et le token d’authentification au notebook. Vous pouvez éditer le fichier slurm-jobid.out ou utiliser la commande
grep token slurm-jobid.out(remplacez jobid par la valeur rendue par la commande sbatch précédente ) La ligne qui nous intéresse ressemble à
http://gpu01:8080/?token=817f5205e74d91f0f670d567945e45c4514a6ef1aed49e93
Dans cet exemple le nœud sur lequel s’exécute jupyter est gpu01, le token est 817f5205e74d91f0f670d567945e45c4514a6ef1aed49e93
Note
Si le port
8080est déjà occupé le port suivant (8081) sera automatiquement utilisé.
Créer un tunnel ssh entre votre poste et le nœud où s’exécute votre notebook
Le serveur jupyter est un serveur web, en écoute sur un port sur un nœud du cluster. Pour y accéder depuis votre poste vous devez établir un tunnel construit avec le protocole SSH entre un client (votre poste) et un serveur (Leto) en faisant correspondre un port de votre poste au port distant utilisé par le notebook jupyter, et ce à travers une connexion SSH.
Pour mieux comprendre ce qu’est un tunnel ssh vous pouvez utiliser cette représentation proposée par mobaxterm :
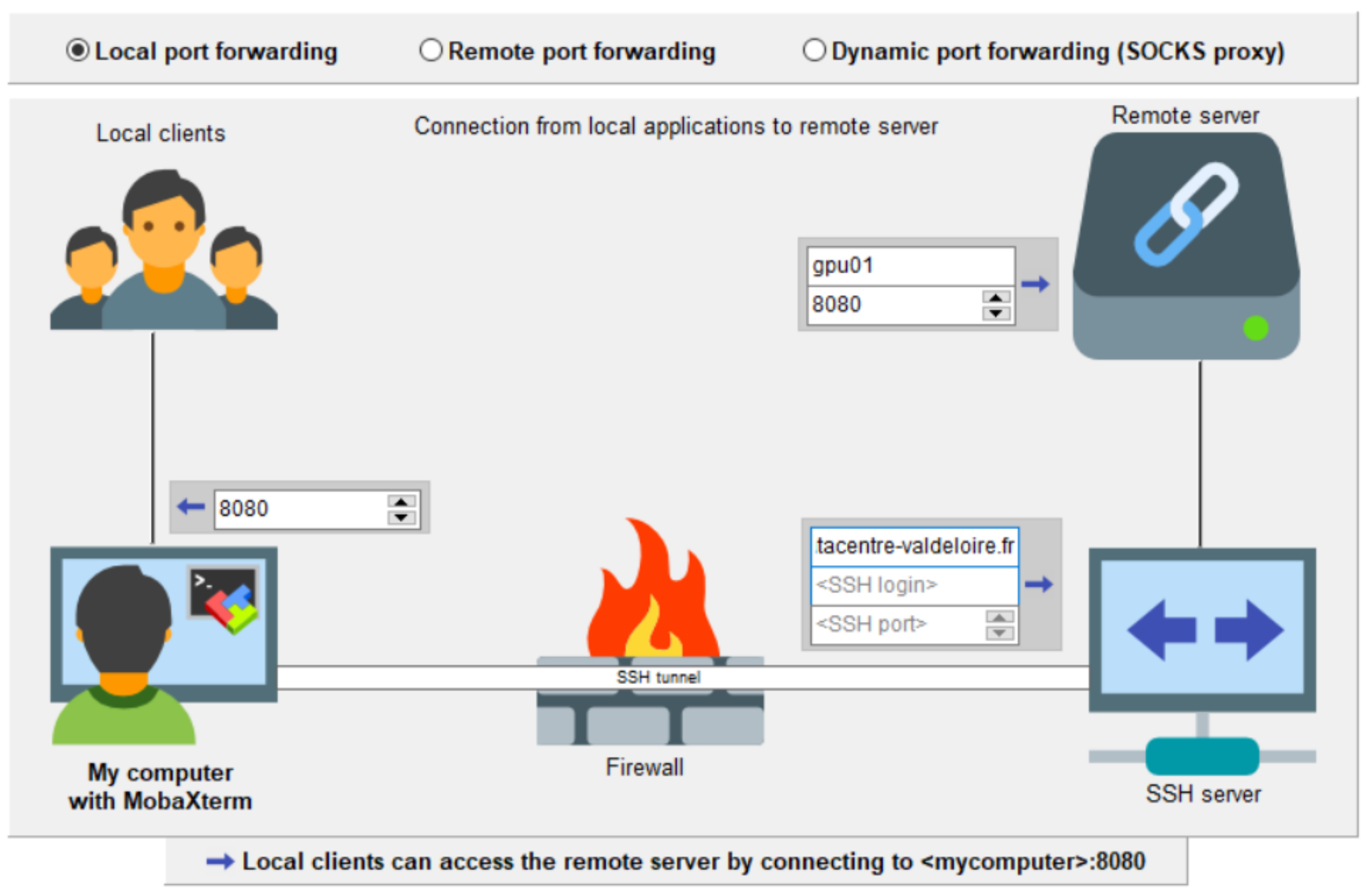
Avec Mobaxterm
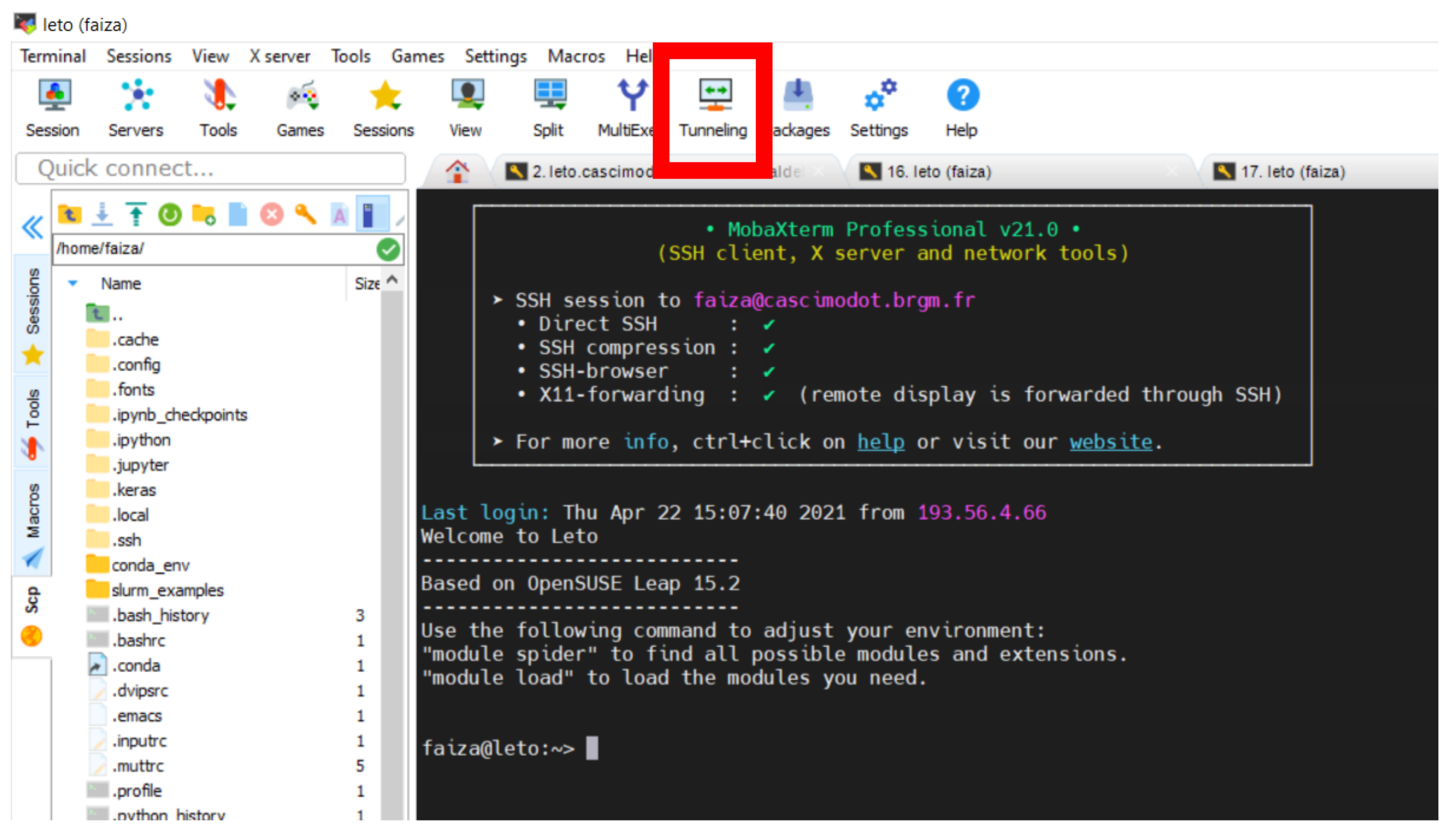
Dans Mobaxterm démarrez MobaSSHTunnel en cliquant sur l’icône Tunneling
La fenêtre MobaSSHTunnel s’ouvre. Cliquer sur New SSH Tunnel
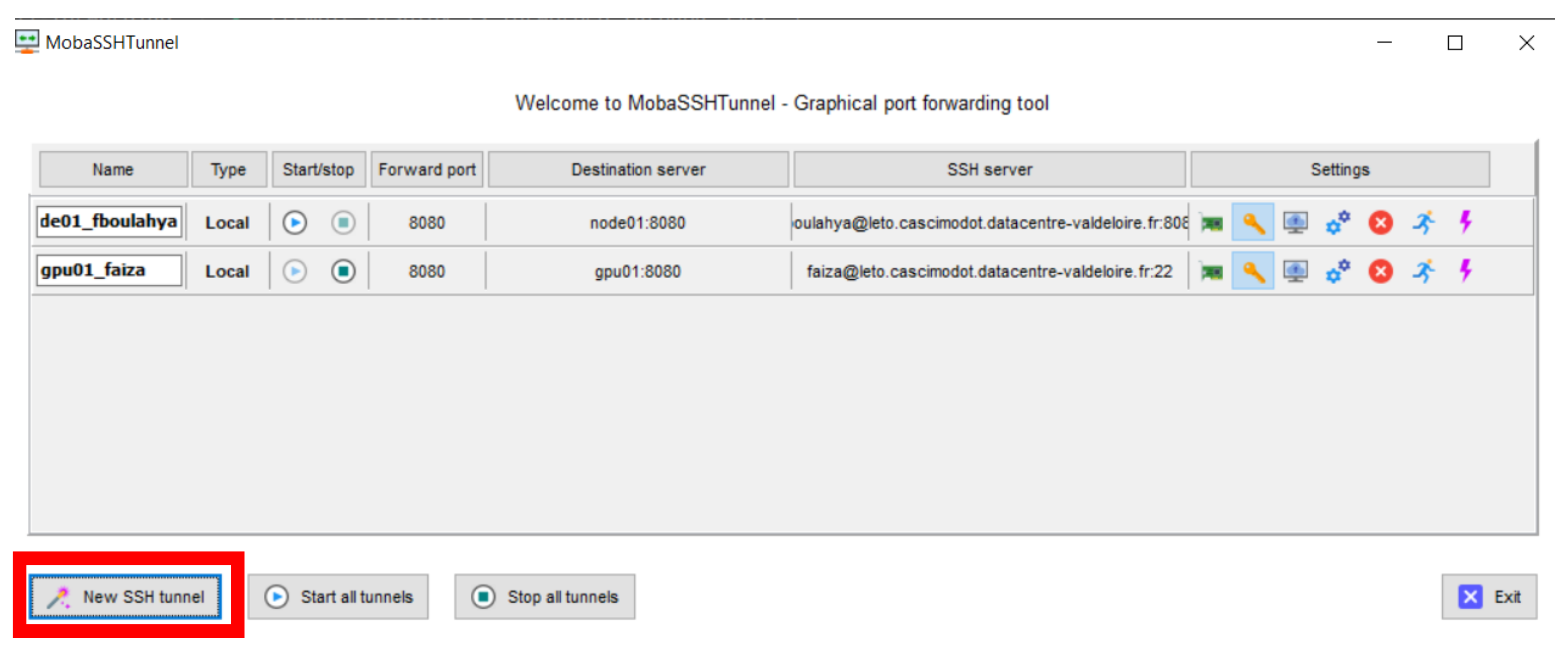
Une fenêtre pour configurer votre tunnel s’ouvre.
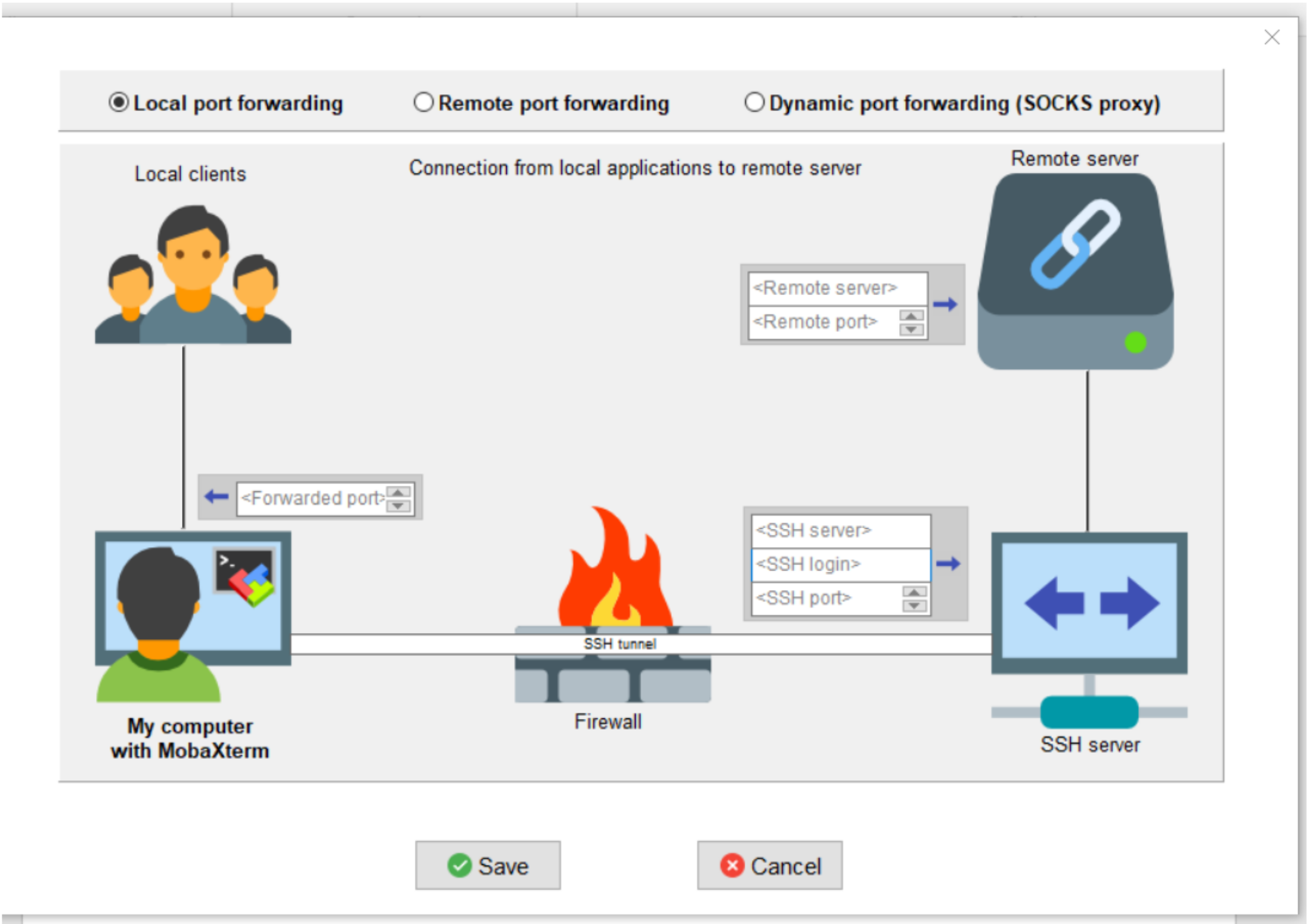
Laissez Local port fowarding coché et renseignez les champs de la manière suivante :
Fowarded port : 8080 (il s’agit du port local de votre machine)
SSH server : leto.cascimodot.datacentre-valdeloire.fr
SSH login : votre login sur Leto
Remote server : le nœud où s’exécute votre notebook
Remote port : 8080
Cliquez sur Save. Dans la fenêtre MobaSSHTunnel une ligne a été ajoutée. Vous pouvez donner un nom à ce tunnel. Vous devez ensuite ajouter votre clé privée ssh nécessaire à la connexion sur Leto. Pour cela, cliquer sur l’icône clé au bout de la ligne
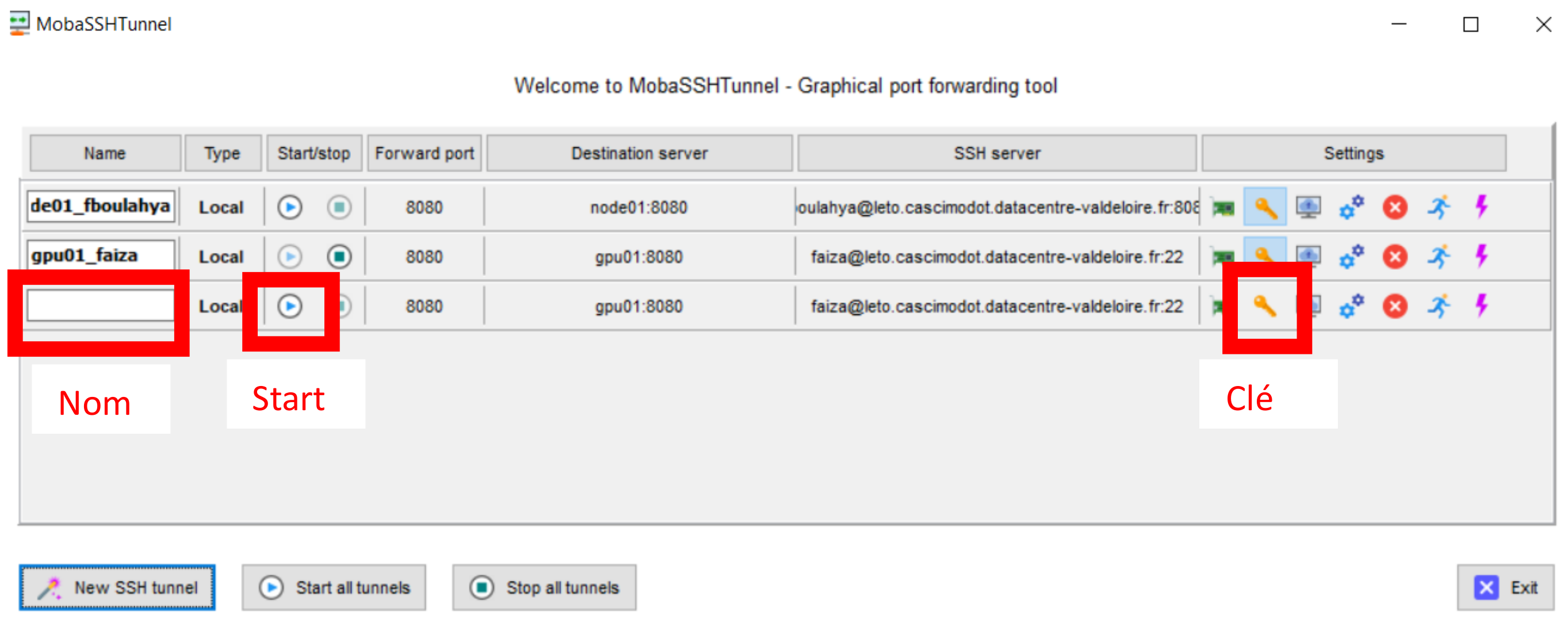
Vous n’avez plus qu’à cliquer sur la petite icone start pour que le tunnel démarre. Nom Start Clé
Avec putty
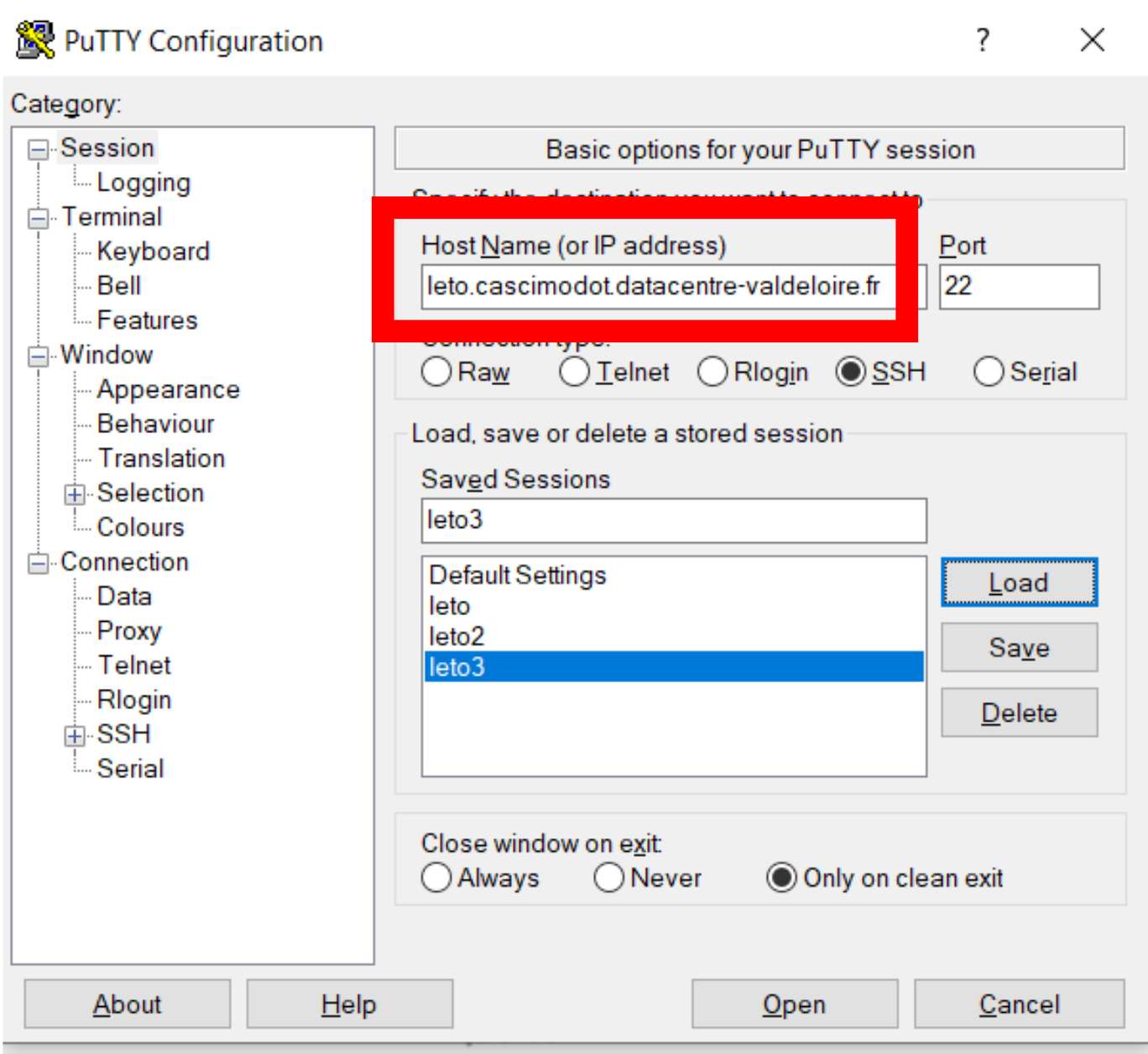
Vous devez renseigner un profil de connexion putty de la manière suivante : Dans session / Host Name : leto.cascimodot.datacentre-valdeloire.fr
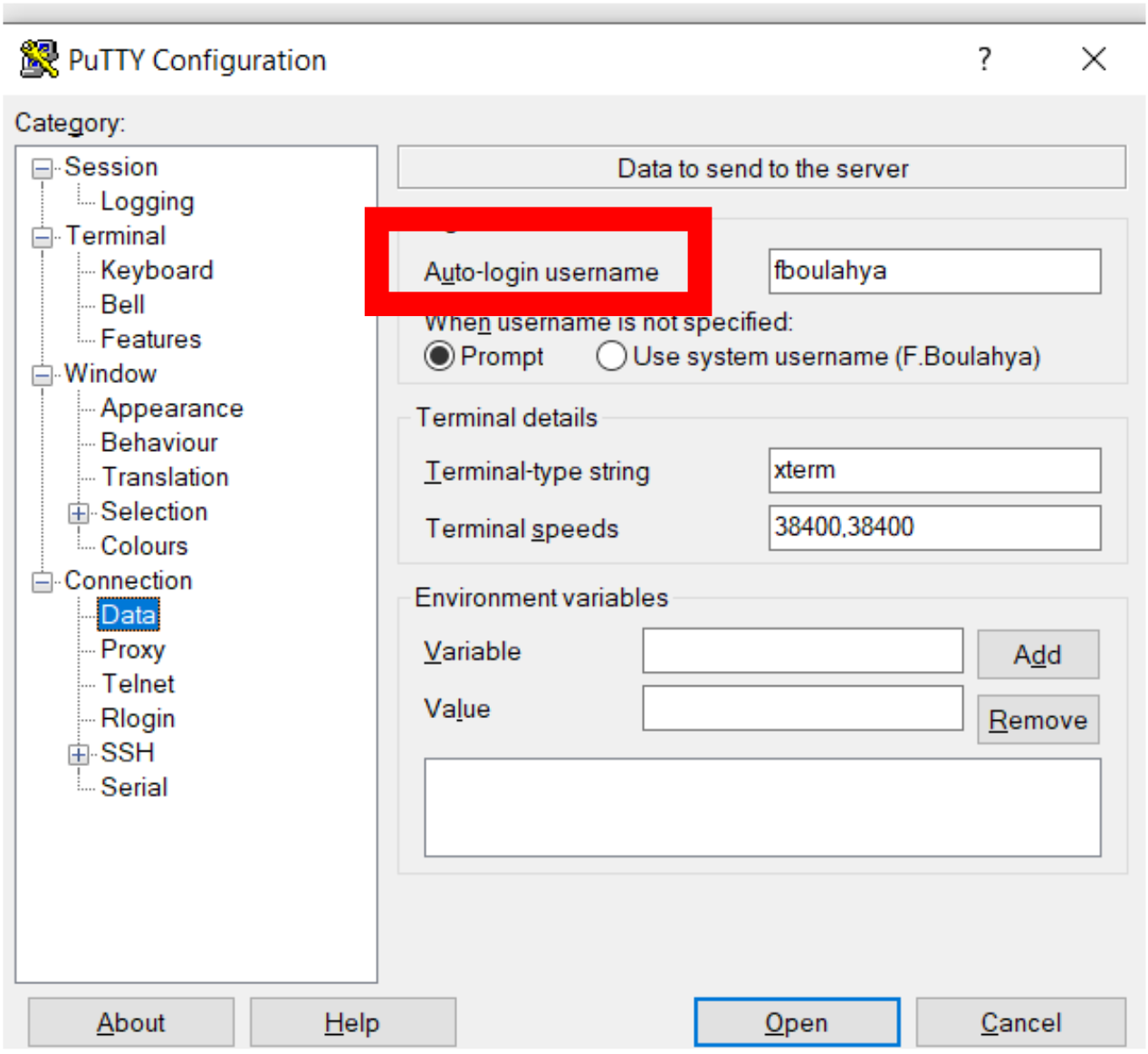
Dans Connection / Data / auto-login username : votre login de connexion à Leto
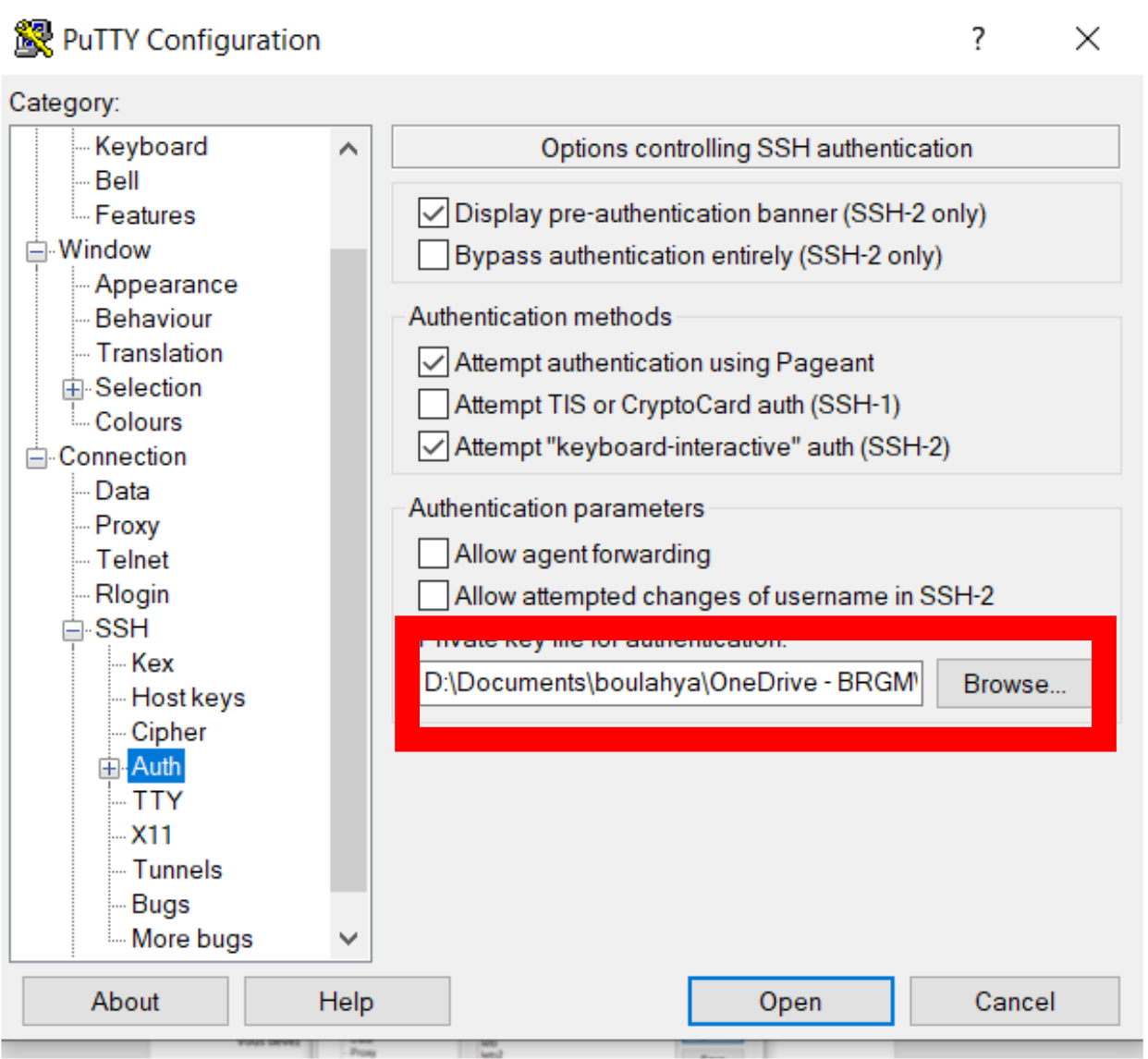
Dans Connection / SSH / Auth renseignez votre clé privée
Dans Connection / SSH / Tunnels / Source port : 8080 (port local de votre machine)
Dans Connection / SSH / Tunnels / Destination : node:8080 (où node est à remplacer par le nœud où s’exécute votre notebook)
Cliquez sur add
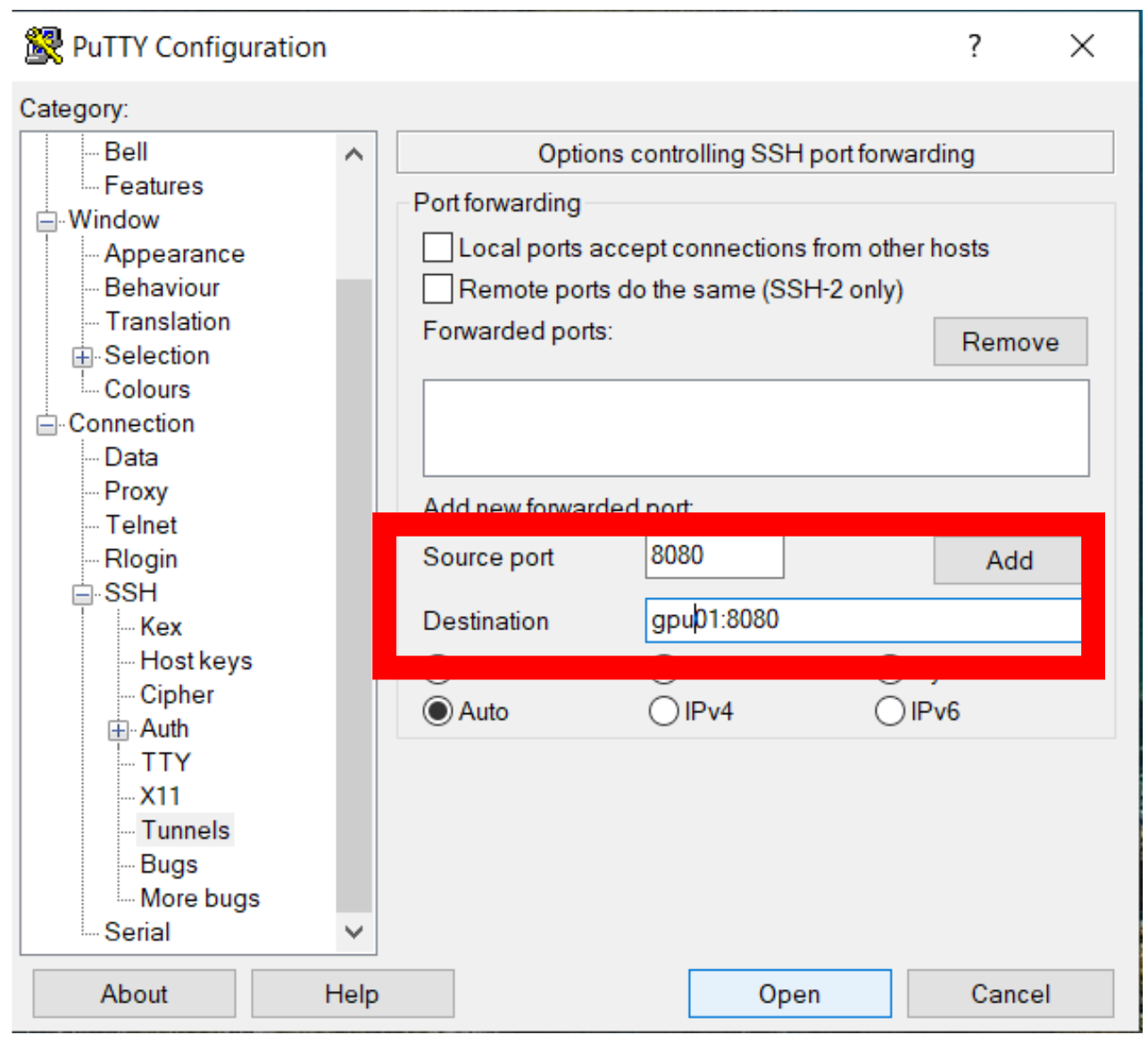
Enfin, cliquez sur open. Un terminal s’ouvre sur Leto
Depuis Linux en ligne de commande (CLI)
La commande pour créer un tunnel ssh vers le nœud nodexx pour l’utilisateur toto est :
ssh -N -L 8080:nodexx:8080 toto@leto.cascimodot.datacentre-valdeloire.fr
Le notebook
Dans votre navigateur internet tapez l’adresse http://localhost:8080
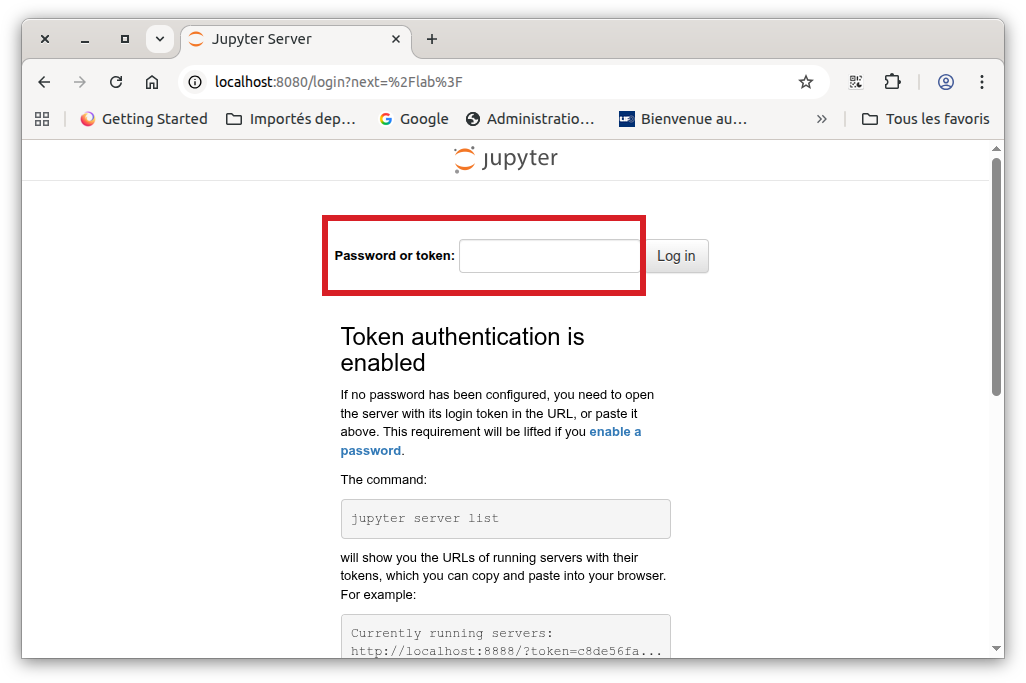
Dans le champ token saisir le token que vous avez récupéré dans votre fichier slurm-jobid.out Vous obtenez votre page jupyter listant le contenu de votre compte (de votre home directory)
Sélectionnez un environnement dans le notebook
Cliquez sur une icône pour sélectionner l’environnement virtuel qui vous convient. Si vous n’avez pas lié d’environnements virtuels à jupyter vous ne verrez que Python 3

Carte GPU
Vérification avant de pouvoir utiliser les gpu
Pour pouvoir utiliser les gpu vous devez être dans le groupe linux video.
Pour vous assurer que vous êtes dans ce groupe taper la commande groups. Si video n’apparait pas, veuillez nous contacter.
Ressources GPU
Dans votre script de soumission SLURM (my_notebook.job) ajoutez une des 2 partitions gpu avec une de ces 2 lignes suivantes :
#SBATCH -p gpu-intel
#SBATCH -p gpu-amd
Ajoutez également le nombre de gpus (x) que vous voulez utiliser
#SBATCH --gres=gpu:x
Note
Rappel pour chaque nœud :
partition gpu-intel : 4 x Nvidia Tesla V100 (Nvlink)
partition gpu-amd : 3 x Nvidia Tesla V100 (PCIe)